


Wow, it's been a while since I've reported in, hasn't it?
Catching up
I've been busy with a lot of things, but the most relevant to this blog is the implementation of a CMS layer over my game Mnemosyne's database. The evolution of the content and data layer has been ongoing for literal years, from the plain JSON and YAML text files of Ranvier, to a basic MongoDB implementation with custom admin panel, to a fully-featured CMS-and-DB all-in-one solution. For context, CMS stands for "Content Management System", and is a term used to describe a web application that allows you to create, edit, and delete content. In this case, the content is the data that makes up the game world, such as NPCs, items, areas, and so on.
That said, implementing it was not without issues, many of which were minor inconveniences where I had to tweak some settings or customize things for the unique task of creating content for a game. Now that it's implemented, I find creating content in it to be hugely convenient and safe compared to editing raw text files or database fields. However, this blog post will cover a potentially killer issue I ran into and then resolved regarding massive, mysterious lag spikes when playing the game.
As a heads-up, parts of this blog assume some familiarity with JavaScript and TypeScript, NodeJS, and general web development terminology, but I'll try to link to information when appropriate. With that said, let's dive in.
Let's talk about Payload
This last solution came in the form of Payload CMS, a full-stack TypeScript solution that I've been experimenting with for a while. An open source project by a company of the same name, Payload lets you define a config for each of your pieces of content and automatically generates an easy-to-use admin panel (in React) for you, for each of them. I chose it because it fit very well with my existing tech stack.
Disclaimer: For those who are a bit less web-dev savvy and who are new to terms like GraphQL, REST, React, and so on, that's fine. Just know that the Payload library runs on a server or in the cloud, generates ways for you to talk to it over a network, generates its own admin panel user interface, and also lets exposes a way for you to manipulate data on the server itself. All you need to do is configure the documents you want to be able to create. I do plan on making a more general post about my experiences with using Payload CMS to create game content, in the future, so look forward to that.
Payload CMS is in TypeScript, built on top of MongoDB and generates GraphQL and REST endpoints for you to use, if you so desire. Or you can simply interact with the data by using Payload's "local API", in other words importing the Payload library and using it to interact with the database directly on the server side.
This last option sounded great to me as I worked to integrate the CMS into my game server. I would be using it, after all, not simply to craft content for the game, but also to act as a compatibility layer over top of all of my persisted game data -- player accounts, characters, world state, and more. By pulling in the Payload library, I could easily load in various bits of data when the server spun up (either via a custom Ranvier Datasource or simply calling payload.find directly to pull in data not directly tied to a game entity), and similarly create or update documents when the game needed to save changes, all without having to spin up a second server, a second database instance, or anything else that my lazy dev self simply did not want to do.
A disclaimer of sorts
I want to be clear before I proceed here... I would absolutely recommend Payload if you're looking for a CMS solution built with TypeScript, React, and MongoDB. It's generally been powerful and easy-to-use which is a hard combo to find. But it's not perfect, and I ran into some issues when trying to use it as a data layer for my game, that were likely of my own making.
Okay, but what's the problem?
After getting everything incorporated nicely and building out a test area, I finally spun my game back up to find that many things worked exactly the way I'd hoped. I spent a few weeks polishing rough edges left between the game server and the Payload library (bits of glue code to transform data), but then started to realize that there was a big problem. Whenever I logged in to a character, there were a few seconds of lag. At first, I thought something was wrong with the client side but I ruled that out -- after all, I'd made few changes there. Payload seemed the most likely culprit, but where? Loading data from the database was fast, the transforms were fast, and the game was fast once I was logged in... or was it?
After playtesting for quite some time, I realized that every couple of minutes, I would be hit with another lag spike. Similarly, after completing a step in a quest, I would be hit with a lag spike. Then, it hit me -- saving the player character was causing a lag spike! The player character was saved automatically when you logged in, and an autosave function was called every few minutes. And of course, after completing a quest or any similar achievement, the player character would again automatically save. I tried manually saving and then immediately hitting some movement keys, and that proved out my theory. The server would begin the save process, then freeze entirely for a few seconds, then immediately register all of the movement! I was on to something.
I found this handy YouTube tutorial from Web Dev Cody on debugging NodeJS performance issues, since to date I've actually had little cause to do such benchmarking, and learned about CPU profiling and flame graphs. Below you can find a flame graph prior to the changes I'll be discussing in this post:
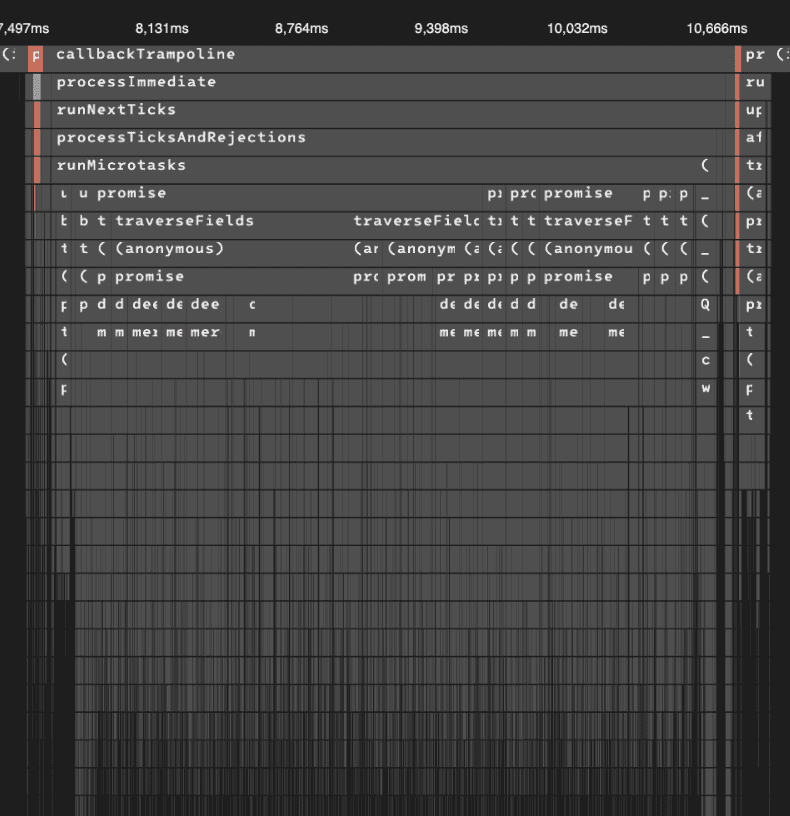
To illustrate the problem, the left-hand orange spike is the game server calling its save function. The right hand spike is the game server calling the movement functions. The giant plateau in between is Payload CMS using up three seconds of CPU time to do a lot of pre-processing before saving to MongoDB. Not ideal! And to be honest, I'm not sure why it's happening like that -- perhaps it is something with the way I had configured Payload, or it may be an inherent flaw with the library (which otherwise runs fairly well, is easy to use, etc.). Clearly, Payload was engineered to be a solution for an app that either doesn't need realtime performance (e.g. responding to player input seemlessly), or to be used as a standalone CMS server only handling the data layer. I needed to find a way to make it work for my use case.
The solution
For a while, I considered just spinning up Payload as its own server, Dockerizing the whole thing, and having the game server communicate with the Payload server via REST or GraphQL. After all, that's how it was devised to work, right? But I'd already written all of this glue code using the Payload local API, and the game engine's custome datasources I'd written also used the local API. What if I could be supremely lazy and create a solution that would require minimal changes to the existing code?
That's when I remembered that it was possible in NodeJS to spin up a child process to handle async tasks. In doing so, assuming it was on a machine with more than one CPU core, I could offload all Payload local API calls to that process, and free up the main process to handle game logic and input/output (more on this later...).
I started by just kicking off a forked process that did some very basic things. To kick off the process, I created this file which was imported and ran when the server started up:
// create-payload-process.ts
import { fork } from 'child_process';
const childProcess = fork(`${__dirname}/payload-process-manager.js`);
// Here the payload prop includes data pulled from the environment that payload needs to be able to init:
childProcess.send({ type: 'initialize', payload: { mongoURL, secret } });
As you can see, when calling Node's child_process.fork, you supply it with a script for the new process to execute. This script should include a process.on('message', callback) listener, which will be called whenever the parent process sends a message to the child process. In this case, I'm sending a message to the child process to initialize Payload, and passing it the data it needs to do so.
Note: For better or worse, I used the property payload here to mean 'data payload' even though it is also the name of the library I'm using... oh well. It has nothing to do with the Payload library, so don't get confused. I guess I could refactor it to be 'data' or something, but I'm lazy.
Here is the humble beginnings of what I called the "process manager", which would then import everything needed to spin up Payload and listen to events from the main process:
// payload-process-manager.ts
import express from 'express';
import payload from 'payload';
// Here we can use a Promise to prevent race conditions; we ensure we always wait for Payload to be initialized before using other Payload methods:
let resolvePayload;
const payloadInitialized = new Promise((resolve) => {
resolvePayload = resolve;
});
// Set up express, which Payload uses under the hood to serve endpoints that it talks to using the frontend it generates:
const app = express();
const port = 3004;
// Start listening for messages from the parent process:
process.on('message', handleCMSMessage);
async function handleCMSMessage(message: PayloadIPCMessage) {
if (message.type === 'initialize') {
await initializePayload();
}
}
So, this manager would listen to any messages from the main process, which it would expect to be an object with a type property so that it can properly decide how to handle each message based on its type.
First, we will need to handle the "initialize" message by initializing Payload:
// payload-process-manager.ts
import payload from 'payload';
// This initializes Payload and resolves the promise we created earlier:
async function initializePayload({
secret, mongoURL,
}) {
app.listen(port, () => console.log(`[payload-process] Express listening on port ${port}!`));
// See Payload's docs for more on this:
await payload.init({
secret,
mongoURL,
express: app,
});
resolvePayload();
// If payload initialized correctly, this should log out the names of all of my collections, such as "npcs", "items", "areas":
console.log('[payload-process] Payload initialized with ', payload.collections);
// Finally we send a message back to the parent process to let it know that we're done initializing:
process.send?.({ type: 'initializationResult', payload: { collections: payload.collections } });
}
And this ended up working! Payload would spin up, connect to the MongoDB instance running locally, log out the collections I'd already created, and I could even navigate to localhost:port in my browser and use the admin panel.
Step-by-step, what we've done so far
So, to recap, we've done the following:
-
Investigated the issue using a flame graph and identified that Payload CMS was causing high CPU usage during pre-processing before saving to MongoDB.
-
Created a child process to handle Payload API calls, freeing up the main process to handle game logic and input/output.
-
Developed a PayloadAdapter interface and a PayloadChildProcessAdapter class to manage communication between the main process and the child process.
-
Proved that the child process can initialize Payload and perform message passing with the main process.
If all you're looking for is an answer to the question "how do I offload some work in NodeJS to another process to free up the CPU?", then you can borrow the abovementioned code, close out your browser tab, and go outside for a while to stare at a tree or something. But if you're trying to to do something as specific as interface with some kind of asynchronous library, then you'll need to do a bit more work.
Extending this solution
While the above solution was enough to get Payload up and running in a child process, I had to make some changes to ensure that all of the places in my code that were using the Payload local API would now use the child process instead. I did this by creating an adapter around the inter-process communication (IPC).
Getting TypeScript on our side
If I were successful in this attempt to create an adapter, how would I know? Ideally, the only change I would need to make would be to change some imports, and otherwise all of the calls to payload would work the same way. To pull this off, I created an interface that I would use to ensure that any implementation of an adapter would match the way I was using Payload already:
// payload-adapters.ts
import uuid from 'node-uuid';
import type payload from 'payload';
type Payload = typeof payload;
type CreateParams = Parameters<Payload['create']>[0];
type CreateReturnValue = Awaited<ReturnType<Payload['create']>>;
type FindParams = Parameters<Payload['find']>[0];
type FindReturnValue = Awaited<ReturnType<Payload['find']>>;
type FindByIdParams = Parameters<Payload['findByID']>[0];
type FindByIdReturnValue = Awaited<ReturnType<Payload['findByID']>>;
type FindGlobalParams = Parameters<Payload['findGlobal']>[0];
type FindGlobalReturnValue = Awaited<ReturnType<Payload['findGlobal']>>;
type UpdateParams = Parameters<Payload['update']>[0];
type UpdateGlobalParams = Parameters<Payload['updateGlobal']>[0];
interface PayloadAdapter {
create: (options: CreateParams) => Promise<CreateReturnValue>;
find: (options: FindParams) => Promise<FindReturnValue>;
findByID: (options: FindByIdParams) => Promise<FindByIdReturnValue>;
findGlobal: (options: FindGlobalParams) => Promise<FindGlobalReturnValue>;
update: (options: UpdateParams) => Promise<void>;
updateGlobal: (options: UpdateGlobalParams) => Promise<void>;
}
class PayloadChildProcessAdapter implements PayloadAdapter {}
To build the interface, we first get the parameters and return values for the methods we want to implement. In some cases, for ease of use of the type, I did not opt to implement the full type of the payload methods, which is why I used these helper types instead of just using TypeScript's Pick helper.
Also note that I'm using the Awaited<T> helper type from the TypeScript 4.5 release, which is a way to unwrap Promise values. In every case, we re-wrap the type in a Promise when defining the adapted method's return values, but there are some cases where I wanted to use the unwrapped type within a method, so for consistency I unwrapped every return type.
After finishing building this interface, I ended up with some red squiggly lines under my class PayloadChildProcessAdapter declaration that let me know I had some work to do. I needed to implement all of the methods in the interface, and make sure that they would send the right messages to the child process, and then wait for the child process to respond with the right data before resolving the Promise.
Messaging back and forth
To ensure compatibility when messaging back and forth, I added another interface to the mix, along with a type that would be used to ensure the type of the message matched what we expected to be implemented:
// types.ts
export interface PayloadIPCMessage<T = any> {
type: IPCMessageType;
payload: T;
uuid: string;
}
export type IPCMessageType =
| 'create'
| 'createResult'
| 'error'
| 'find'
| 'findResult'
| 'findByID'
| 'findByIDResult'
| 'findGlobal'
| 'findGlobalResult'
| 'initialize'
| 'initializationResult'
| 'update'
| 'updateGlobal'
| 'updateResult'
| 'updateGlobalResult';
Great, now each method had its own corresponding message type, as well as a result message type. Each message would also carry a payload that could differ based on the message (I reserve the right to make types stricter, but for ease of implementation I just defaulted to any for the generic type here). Finally, each message would also carry a uuid property, which would be used to match up the result message with the original message. This would be important to prevent timing issues when sending multiple messages at once.
Implementing the 'find' API
I won't go over every single method here as they are rather repetitive -- so if I share just one example, you should be able to extrapolate the rest. Let's start with the find method, which is used to find one or more documents in a collection. Here's the implementation in the Payload child process:
// payload-process-manager.ts
async function handleCMSMessage(message: PayloadIPCMessage) {
// ... other message handling code
if (message.type === 'find') {
await payloadInitialized;
const result = await payload.find(message.payload);
console.log('[payload-process] find result: ', result);
process.send?.({ type: 'findResult', payload: {
docs: result.docs
}, uuid: message.uuid });
}
// ... more message handling code
}
As you can see, we're waiting for the payloadInitialized promise to resolve before calling payload.find, and then sending a message back to the parent process with the result. This means that the child process will not try to call payload.find until after Payload is initialized. Then, it uses the initialized Payload library to fetch a document from the collection specified from the parent process. Finally, it sends a message back to the parent process with the results. Since Payload is built on top of a document database, we can rest assured that the results it returns are easily serializable into JSON -- something that process.send will do automatically for us.
The parent process will then resolve the Promise that was returned by the find method, and the code that called payload.find will continue on its merry way. Here's what that looks like in our adapter back in the parent process:
// payload-adapters.ts
class PayloadChildProcessAdapter implements PayloadAdapter {
// ... constructor, other methods...
// Helper method to ensure type safety of the messages we send to the child process:
sendMessage(message: PayloadIPCMessage) {
this.process?.send?.(message);
}
// Implementation of the 'find' method:
find(options: FindParams): Promise<FindReturnValue> {
return new Promise((resolve) => {
const uuid = this.getUuid();
this.sendMessage({
type: 'find',
payload: options,
uuid,
});
// Note that we keep the listener around so that we can remove it once the results are received:
const listener = (message: PayloadIPCMessage) => {
console.log('[payload-adapter][find] Received message: ', message);
if (message.type === 'findResult' && message.uuid === uuid) {
resolve(message.payload);
this.process?.removeListener('message', listener);
}
}
this.process?.on('message', listener);
});
}
}
As you can imagine, implementing the rest of the Payload methods used by Mnemosyne's game engine followed a very similar pattern. Once I'd done so, I could just update the imports like so:
// server.ts
import payload from 'lib/payload-adapters';
await payload.find({ collection: 'npcs', filters: { name: 'Bob' } });
...and it simply worked! I ran the game, loaded a pre-existing character, and found that the lag spikes were gone. I ran the flame graph again, and found that the plateau was gone, and the game was running smoothly. I was able to save my character, and move around immediately after. Success!
Flame graph of the game server's CPU usage after the changes
{kind=link}
Or at least, semi-success. I found that when I tried to create a brand-new character, the child process crashed entirely, preventing the game server from being able to continue interacting with Payload. Ouch.
Looking at the pattern used for determining if a Player already existed in the database, I found a pattern like this:
// load-player.ts
try {
// Check to see if this player already exists
const player = await payload.find<Player>({
collection: 'players',
filters: {
name: playerName,
},
});
// ... load existing player into the game
} catch (err) {
if (err.message === 'No documents found') {
// ... create a new player
} else {
throw err;
}
}
One pattern used by Payload is that it throws errors when it can't find a document, rather than returning null or something similar. This is fine, but it means that we need to catch those errors and handle them. In this case, the error was occuring in the child process, which has no exception handling, which was then crashing the process. I needed to find a way to catch those errors in the child process, and send them back to the parent process to be handled.
Handling errors in the child processs
My solution, which may not be the optimal, was to wrap the entire body of the child process' manager's handleCMSMessage function in a try/catch block, and then in the catch section, send any error message back to the parent process as its own type of message:
// payload-process-manager.ts
async function handleCMSMessage(message: PayloadIPCMessage) {
try {
//... handle messages
} catch (e) {
console.error('[payload-process] Error handling message: ', e);
const errorPayload = e?.message || e;
process.send?.({ type: 'error', payload: errorPayload, uuid: message.uuid });
}
}
Then, in the parent process, I added a method for handling errors. While I was at it, I also made a generic "kitchen sink" method for sending and listening to messages since I found that the bodies of all of the methods ended up largely being the same. Normally, I would hold off on this pursuit of DRYness, but at this time it felt necessary.
// new generic method:
sendPayloadMessage<ParamType extends ParamTypes, ReturnType extends ReturnTypes>(options: { type: IPCMessageType, payload: ParamType }): Promise<ReturnType> {
return new Promise((resolve, reject) => {
const uuid = this.getUuid();
this.sendMessage({
type: options.type,
payload: options.payload,
uuid,
});
const listener = (message: PayloadIPCMessage) => {
console.log(`[payload-adapter][${options.type}] Received message: `, message);
if (message.type === `${options.type}Result` && message.uuid === uuid) {
resolve(message.payload);
this.process?.removeListener('message', listener);
}
try {
this.handleError(message, listener, uuid);
} catch(e) {
// Note that we have to reject here rather than letting the error propagate from the listener, or else both processes will crash:
reject(e);
}
}
this.process?.on('message', listener);
});
}
// new error handler:
handleError(message: PayloadIPCMessage, listener: (message: PayloadIPCMessage) => void, uuid: string) {
if (message.type === 'error' && message.uuid === uuid) {
console.error('[payload-adapter][handleError] Error: ', message.payload);
this.process?.removeListener('message', listener);
throw new Error(message.payload);
}
}
Important to note is that I had to explicitly catch the error again and then reject the promise with the error message. Letting the exception propagate from the listener would kill the child process (and the game server as a whole, in this case). With this change, the error message would be properly propagated to the caller, where the exception handling could correctly identify that the Player document (in this example) did not exist yet.
With this change, my implementation of the Payload adapter was feature-complete, at least for my current use cases. I can move on with my life!
Future improvements
In the future, I would likely want some more robust error handling, for example restarting the child process if it is killed for some reason.
In addition, it may make sense at some point to create adapters for REST or GraphQL interaction with a remote Payload server, which would allow me to use the same code for both local and remote Payload instances. This would be useful for testing, for example, or for running the game server and the Payload server on different machines. Eventually, when my game is hosted in the cloud in some form, this may be necessary.
On a more trivial note, the Payload process manager may be due for a refactor, as it's a bit messy and could be more DRY. This would be along the lines of the refactor done to the adapter itself, too.
Finally, at no point when writing this code did I add unit or integration tests, which may be smart to have if I need to make big changes to it.
Extended recap
If you've made it this far, kudos to you! Here's a recap of what we've done in this extended section:
-
Finished implementing the Payload API and used UUIDs to keep track of messages passed.
-
Made changes to existing code to use the PayloadChildProcessAdapter instead of directly importing Payload.
-
Used a flame graph to prove we had successfully eliminated lag spikes in the game.
-
Implemented error handling for the child process to catch and propagate errors back to the main process safely.
Reflections
To summarize:
- Payload has been great to use, for the most part.
- Even though I did not use it as designed, I found a workable solution and learned a lot.
- Child process usage in Node can be very powerful, parallelism is great, but it's not a silver bullet per se.
- Always benchmark your code, and don't be afraid to use tools like flame graphs to find the source of performance issues.
- There's probably applications for inter-process communication on the frontend of my online game Mnemosyne as well, using WebWorkers and more.
Thanks for reading! I hope that this was helpful, and I hope that my future posts will be more timely. I'm going to try to write more regularly going forward, and I have a lot of topics I want to cover. So stay tuned!
Resources
Credits
Thanks to the MUD Discord and MUD Slack for reading and offering feedback on this article prior to publication. This beta audience includes but is not limited to users crb, tanni, Spade, Robey, and others.
The hero image is from the WikiMedia Commons, and is licensed under the Creative Commons Attribution-Share Alike 3.0 Unported License. Original artist is Augusto Starita.
Finally, thank you to the PayloadCMS team who helped me get off the ground with Payload and of course for making such a cool and useful project.